Using SQL Server with Aurora
Introduction
This document covers recommendations for the use of MS SQL Server input and output databases with Aurora. Each database created by Aurora has its own schema and table set. Generally speaking, all database write and most read functionality is accomplished from within Aurora's graphical user interface. Within Aurora, users specify a database name and the database server along with login information. Each database has one schema that is entirely and transparently setup by Aurora when the database is created. Individual users and/or individual Aurora simulation runs use their own separate database or in certain instances (for example a scenario analysis where all scenarios will be reported simultaneously) share databases.
It is important to understand that Aurora is using the SQL database simply as an output format (one of many possible) that manages large output data sets and allows queries on that output. The concept of a separate database for a particular set of Aurora simulation output is a concept well supported by SQL Server and mySQL and is used extensively by many Aurora users.
The Aurora architecture does not support an Oracle-style multi-schema environment. We use a very simple concept of creating a separate database for each set of Aurora simulation output. That database will have its own schema created internally by Aurora. The user has little to no control of the database creation or schema being used. It should also be noted that, although in special cases users can share a database with multiple runs or even with other users, they cannot effectively use Aurora with a single SQL output database for all of their uses.
General Recommendations
Version
We recommend using either SQL Server 2019 Express Edition or later on the Aurora client machines or SQL Server 2019 or later on a central server setup specifically for Aurora.
![]() NOTE: The SQL Server Express Edition is a free version of SQL Server that is ideal for many uses with Aurora. It is interoperable with Microsoft developer tools such as Microsoft Visual Studio and Visual Web Developer Express. SQL Express is suitable for most, but not all, Aurora database requirements.
NOTE: The SQL Server Express Edition is a free version of SQL Server that is ideal for many uses with Aurora. It is interoperable with Microsoft developer tools such as Microsoft Visual Studio and Visual Web Developer Express. SQL Express is suitable for most, but not all, Aurora database requirements.
Configuration (Hardware)
We recommend following Microsoft’s system requirements for installing and configuring SQL Server. Total space requirements will depend on planned use, but initial planning should provide for at least 250 GB.
Configuration (General)
We don’t require any special configuration for SQL Server. In our testing the default setup configuration works fine. We have developed a few guidelines as a result of our internal testing. These guidelines are as follows:
- The Aurora users will need database create and drop rights.
- A central SQL Server should not be shared with other departments (i.e. accounting backend) as Aurora’s use of the server will generally be incompatible with other interactive uses.
- The server setup should be changeable as the needs of the Aurora users change (i.e. plenty of disk space).
- It should be setup to handle very large databases – possibly being larger than 10GB each.
- If the SQL Server to be used with Aurora will be accessed over a network, the bandwidth requirements could potentially be very large and the server should be located as close to the users as possible or with a very high bandwidth connection to the users.
- If the goal of the SQL deployment is for multiple users to share an input database or have multiple users share a single output database – appending the data within it – it is probably best to use a single SQL Server account rather than have each user connect via Windows Authentication. Remember, each database created by a user is owned by that user and no one else has permission to it unless explicitly granted by the SQL DBA.
Using SQL Queries
You can easily query SQL-type output databases directly from the Aurora GUI and there is a SQL Query Builder tool that will help you automatically generate SQL syntax. For very large output tables, the use of SQL queries will be much faster and consume significantly less memory than the standard load and filter functionality used in Aurora.
The query construction capability is implemented through an easy to use point-and-click window called the SQL Query Builder. For those already familiar with SQL, an ability to directly write SQL syntax is also provided. The SQL Query Builder can be used with either Microsoft SQL Server, MySQL, or the embedded xmpSQL output database formats. It cannot be used with zipped XML or XML output formats.
Advanced Configuration
Specifying Additional Database Creation Parameters
Additional parameters can be specified when creating SQL Server output databases by using the textbox in the SQL DB Setup window (Reporting folder of Simulation Options). These additional parameters are specified by entering Transact-SQL CREATE DATABASE statements into this textbox. Because SQL Server environment configurations can vary greatly, the syntax of these statements is highly dependent on the setup of the SQL Server you are using (e.g. user access rights, folder permissions, etc.). The syntax to use should be the desired Transact-SQL syntax immediately after the following wording:
“CREATE DATABASE thedatabasename ”
For further information on Transact-SQL syntax see Microsoft’s website.
For example, when Aurora creates an output database in SQL Server, the default settings for initial size and autogrowth are 37MB and 1MB respectively. If you wanted to be able to modify those settings the use of the SQL DB Setup textbox would be required. Add the following TSQL clause to the SQL DB Setup textbox, to alter the settings of the output database created by Aurora:
ON PRIMARY (NAME='WECC_California_Default_Output_TSQLTest01', FILENAME='D:\SQLData\ WECC_California_Default_Output_TSQLTest01.mdf', SIZE=1000MB, FILEGROWTH=246 MB)
This is just one example of how adding specific TSQL statements to the SQL DB Setup textbox gives you nearly limitless flexibility in specifying database create parameters.
Valid Database Naming Conventions
The SQL Server database name cannot begin with a number or space, contain embedded spaces, special characters, or reserved words. The database name is referred to as its identifier. Everything in Microsoft SQL Server can have an identifier. Servers, databases, and database objects, such as tables, views, columns, indexes, triggers, procedures, constraints, and rules can all have identifiers. There are additional rules for the naming of database object identifiers which can be viewed at Microsoft’s website.
User Access Rights Information
User Rights, Database Roles and Other Recommendations
Aurora uses SQL Server to store input and output databases and the data in these databases can be controlled and manipulated by Aurora. Aurora users have total control of their database without the use of other applications, and as such, users need appropriate rights to the SQL Server databases with which Aurora connects.
SQL Server database rights or roles recommended:
Database Role: DB Creator role.
Database Rights: Read, write, create and drop.
![]() NOTE: These rights are usually not given freely by Database Administrators, so we recommend using a server specifically designed to host Aurora’s SQL Server input and output databases.
NOTE: These rights are usually not given freely by Database Administrators, so we recommend using a server specifically designed to host Aurora’s SQL Server input and output databases.
Other Recommendations
SQL Server needs to have remote connections enabled with TCP/IP and Named pipes checked.
Tracing Basic Transactions
In certain SQL Server environments, Database Administrators may want more detail on the exact transactions between Aurora and SQL Server. This can be done using a trace that runs a monitoring log for all the transactions. For more information on tracing SQL Server transactions see SQL Server Profiler. The following example is a trace on a standard Aurora run.
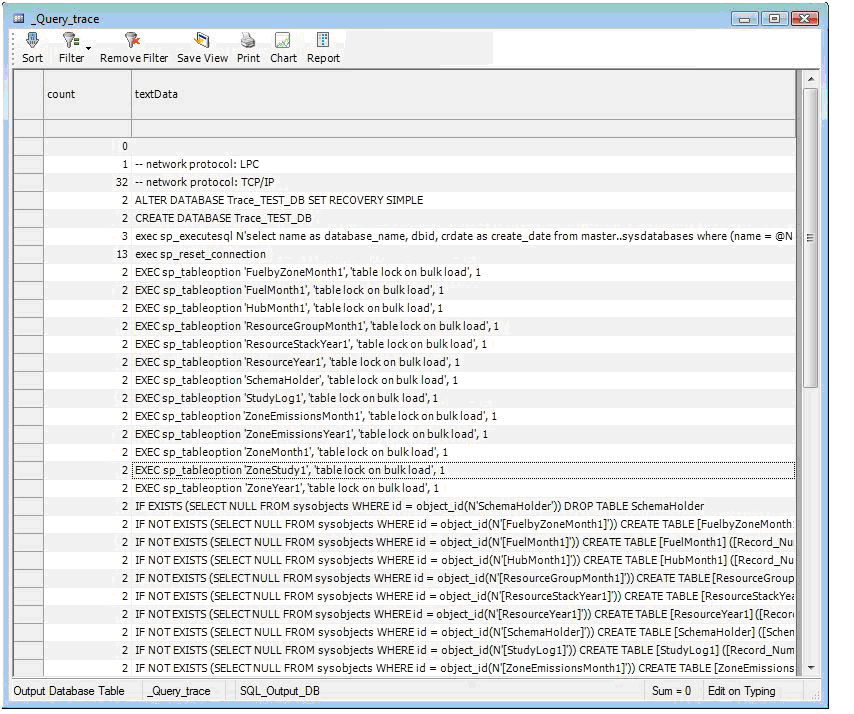
![]() NOTE: The screen shot above shows the results of a SQL query trace created using the SQL Server Profiler on the SQL Server that Aurora is writing output to. The results were sent to a table on the SQL Server which was then queried using an SQL query Quick Views in Aurora. You can find more information on how to setup and use the SQL Server Profiler on Microsoft’s website.
NOTE: The screen shot above shows the results of a SQL query trace created using the SQL Server Profiler on the SQL Server that Aurora is writing output to. The results were sent to a table on the SQL Server which was then queried using an SQL query Quick Views in Aurora. You can find more information on how to setup and use the SQL Server Profiler on Microsoft’s website.
Connection Pooling
Connection pooling is an optimization technique used by ADO.NET to minimize the time (and cost) of opening/closing many identical connections in SQL Server. Aurora is an application that can initiate a large number of TCP/IP socket connections to a SQL Server, and therefore uses SQL Server connection pooling by default. When many instances of Aurora are being run through an automation process where all instances are writing output to a single SQL Server, it is possible to cause TCP/IP port exhaustion.
On many versions of the Windows Operating system, the default range of ports used by client applications is from 1025 through 5000. Under certain conditions it is possible that the available ports in the default range will be exhausted. There are some ways to address this in the Windows registry.
We also found the Windows Sysinternals utility called TCPView to be very helpful when troubleshooting this particular issue.
![]() Using SQL Server with Aurora
Using SQL Server with Aurora