Productivity Enhancements
Aurora, as a productivity enhancer, leads the energy industry with its unique tools.
Scripting and Scheduling
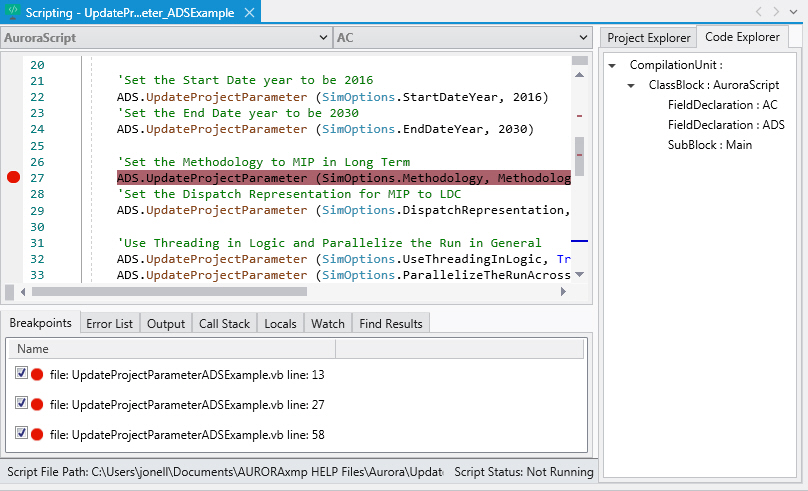
Automate and schedule runs so Aurora can work while you are away. Use Scripting or the Scheduler to make the most of multitasking. You can choose to write scripts in VB, C#, and IronPython. While none of the Aurora‐specific commands have changed, the Scripting window offers some powerful features.
A new summary area at the bottom of the screen offers options like showing lists of breakpoints, compiler errors, output statements, call stacks, and local variables, as well as watch lists and find results. In addition, you can now group script files into script projects to build sophisticated automation tools right in Aurora.
The Scripting tool makes writing and debugging scripts much more user friendly. Aurora's scripting interface uses Visual Basic (VB) to automate many of its utilities. By default, the Scripting window opens a VB file.
Click the Tools > Scripting button to display the Aurora scripting interface where you can create, edit, save, open and run script files or script projects.
Project Scheduler
Schedule recurring project runs or to run multiple projects. The Tools > Project Scheduler functionality is unique to the open instance of Aurora and the scheduler file loaded. This means that different projects/schedules can be run simultaneously in different instances of Aurora.
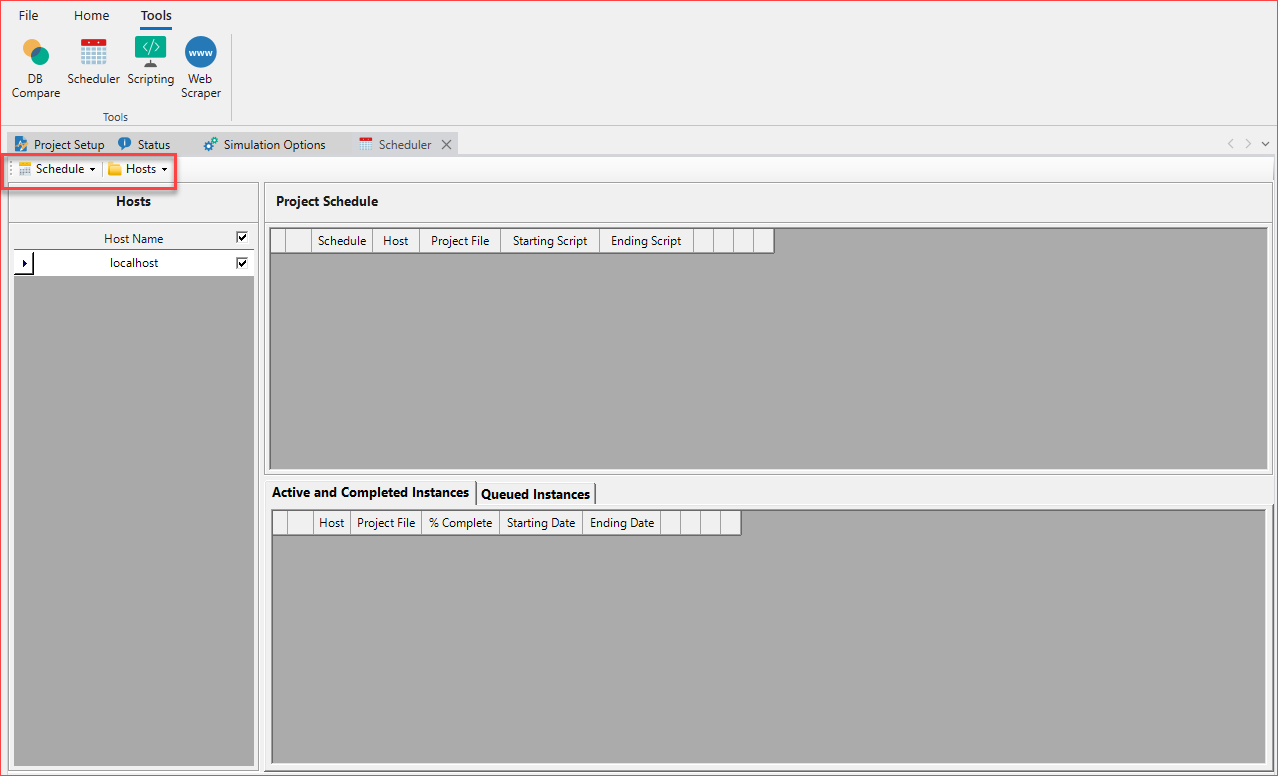
The Project Schedule section lets you select project and scripts.

Parallel Processing
Multi‐Processing Runs
When you add the option to parallelize runs across years, you can divvy up your machine power by spreading out the computational load across machine cores for Study Cases or by Risk Iterations. Simulation Options > Parallel Processing combines all of the Parallel Processing options together.
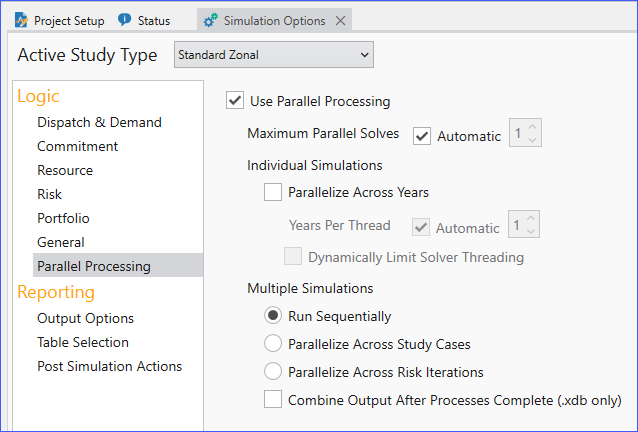
The window above provides simulation options to use multiple processors on a single workstation. By checking the box for Use Parallel Processing, Aurora will make use of multi-processing features like threads and child processes to speed up the simulation runtimes.
Change Output Using Parameters Sets
You can update the output database name and location using Parameter Sets, which is especially useful when running multiple study cases. Parameter Sets provide the ability to create and save multiple combinations of Simulation Option settings within a single Aurora project. Just like Change Sets, they are a convenient and efficient way to set up and run sensitivity studies or scenario analyses beyond a base case set of assumptions.
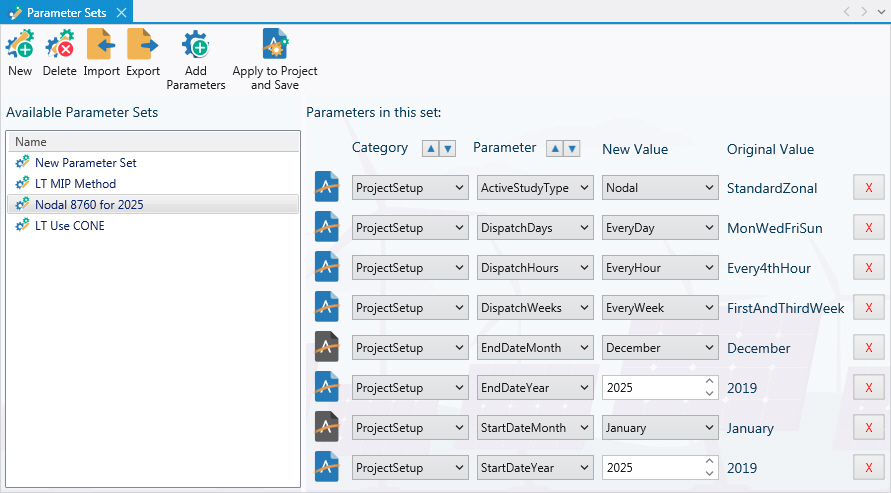
Alternatively, you can also manage setting changes to a project by making copies of project, editing simulation options for the appropriate changes, and then running the projects separately, or use scripting to adjust settings in the studies. However, Parameter Sets provide a more efficient way to manage the variation in assumptions generally associated with sensitivity or scenario analyses.
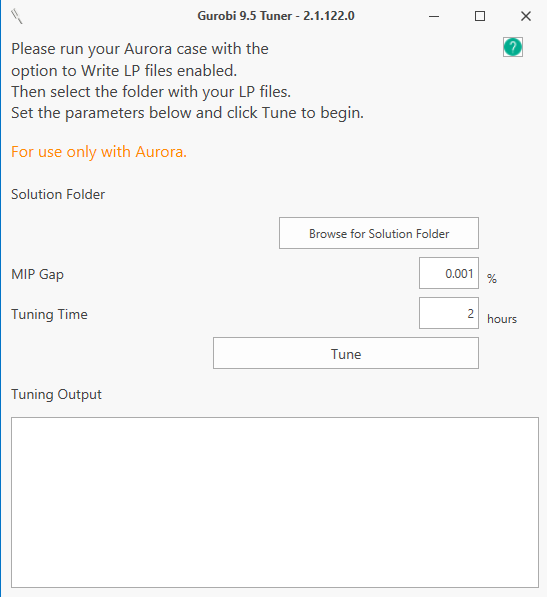
Gurobi Tuner
The Gurobi Tuner is a tool Energy Exemplar has developed to assist new and existing Aurora clients in using Gurobi as their solver. The tuner reads problem data from Aurora simulations written by the Gurobi solver. The tuner works to improve runtime by solving these problem files with many different sets of solver parameters to find what works best for the study. The tuner outputs the best parameters found to a file. This file can then be used in Aurora to run future studies with potentially improved runtimes.
Computational Datasets (CDS)
This window helps you to create Computation Datasets (CDS) and populate them with tables that contain columns based on columns in input, output, memory, and other CDS tables; as well as columns that contain expressions and data created by the user. Expressions can reference other columns in the CDS table and utilize math, comparisons, functions and aggregation. You can access and modify detailed variables during every hour of the simulation and modify data dynamically based on specified conditions.
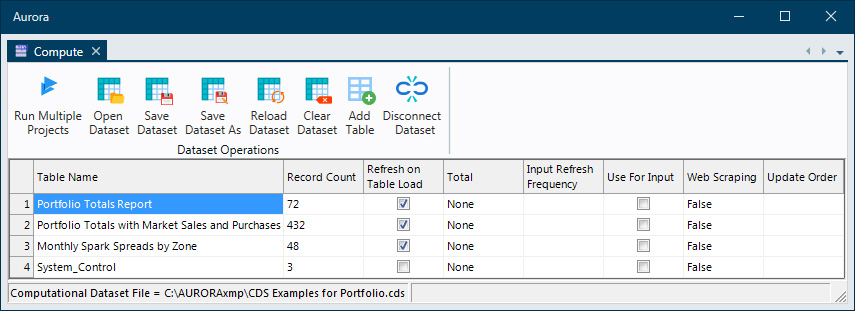
Computational Datasets are stored in a .CDS file which is automatically read when the Computational Datasets window is opened. If no other dataset has been previously created, a default Computational Dataset (CompDataSet Default.cds) is opened initially. To have the current project file load the .CDS file at the beginning of a run, select Automatically Load CDS at Simulation Start in the General form of Simulation Options.
Portfolio Analysis and Optimization
Perform pricing forecasting, Portfolio Analysis and uncertainty analysis with a single tool over virtually any time period.
The capability to perform Portfolio Optimization using a risk-reward framework and a linear optimization model.
The goal of the optimization is to calculate a user-specified number of optimal portfolios – those with the highest reward and lowest risk – given the constraints of the portfolio and its acquirable resources. Each portfolio found by the simulation will lie along the Efficient Frontier, which means that no other portfolio with higher reward at the same risk level exists, and no other portfolio with lower risk at the same reward level exists. The added rigor of this approach will contribute to more credible, defensible results to regulators and senior management.
Memory Tables
View results in memory due to the absolute modeling transparency. Memory tables display only the current hour results. The selected table opens in a new window, with some editing features. See Editing Database Tables or the Right-Click Menu for more information.
Custom Memory Tables can be created for use with Computational Datasets to achieve significantly faster run times. See Custom Memory Tables for more information.
Output Reporting Options
Control Output Results by time periods and conditions; either for the entire analysis or for selected areas, resources, resource groups or fuels.
These capabilities enable greater productivity in setting-up, processing and producing results for decision makers.
Tine Series Data
Aurora has two new options for defining time series data, providing significant flexibility when entering sparse data that follows an hourly, daily, weekly, monthly, or even quarterly pattern. There is no longer a need to duplicate data, but just enter the values and specify exactly which time periods they apply to in a powerful format with available expressions for just about any scenario.
Timeslice Definition
The Timeslice Definition table is used to define a reusable "timeslice" which is shorthand that uses characters and ranges to define time, as opposed to many cells in a typical Time Series table. Once the timeslice is defined it can be referenced from the Time Series Pattern table (below). So instead of having to define 168 hours in a weekly shape, you can now define time with a simplified shorthand.
Time Series Patterns
The new Time Series Pattern table defines custom time patterns for data using key characters (timeslice) or a reference to a defined timeslice. You can have multiple Pattern tables, just like the Time Series Hourly, but be sure to keep unique IDs in each table.
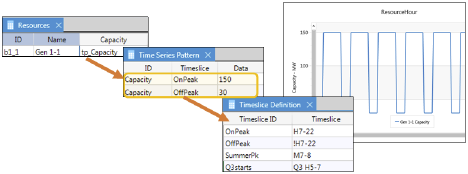
We have extended the Time Series Pattern table with a new Holiday input that can be used in place of the date columns. For the US holidays, the date used will be the observed date and is calculated for each year of the study.
![]() Aurora Features
Aurora Features
![]() Productivity Enhancement
Productivity Enhancement