Nodal Case Input Files
The lower portion on the Nodal tab of the Input Tables Window contains the Network Case Input File information for nodal loadflow cases.
![]() NOTE: All loadflows are subject to either FERC Critical Energy Infrastructure Information ("CEII”) regulations or restricted use provisions of an originating entity. As such, the loadflows can only be delivered to entities which have received and can demonstrate approval from FERC or the appropriate originating entity. Energy Exemplar LLC will require proof of approval prior to delivering regulated data. All such restricted data shall be maintained by Licensee in a secure place and in accordance with all relevant governing regulations.
NOTE: All loadflows are subject to either FERC Critical Energy Infrastructure Information ("CEII”) regulations or restricted use provisions of an originating entity. As such, the loadflows can only be delivered to entities which have received and can demonstrate approval from FERC or the appropriate originating entity. Energy Exemplar LLC will require proof of approval prior to delivering regulated data. All such restricted data shall be maintained by Licensee in a secure place and in accordance with all relevant governing regulations.

Network Case Input Files are zipped XML files that hold selected information from a previously performed loadflow study. The dataset defines the network topology to be used in the nodal study, and holds information describing electrical buses and physical connections and electrical characteristics for transmission lines and transformers. Also specified are generators that were present in the loadflow case, bus demand levels, and area definitions. Multiple nodal cases may be included in this table and a study may use any number of datasets. The use of a case is controlled by the start date. Use the right click menu on the grid to bring up a context menu that will open the dataset or add, delete, and copy cases.
Nodal Case Tables: Loadflow Data
Access the desired loadflow tables by right-clicking or double-clicking on a network case in the Nodal Input Tables Window (shown above). Select Open Network Case and a new Network Case window appears.
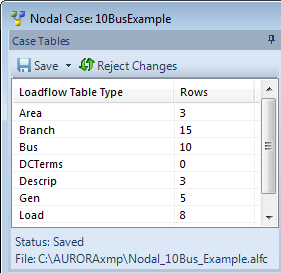
Available Nodal LoadFlow input tables include the following:
|
TABLES INCLUDE |
|||
![]() NOTE: The use of Change Sets is currently not available in the Network Case tables. Saved changes will permanently overwrite the original data.
NOTE: The use of Change Sets is currently not available in the Network Case tables. Saved changes will permanently overwrite the original data.
Nodal Case Properties
The Nodal Case Properties form is used to set various properties pertaining to a loadflow case.
-
Network Case IDNetwork Case ID
An ID for the network case or loadflow case. This entry can be used to associate a specific nodal data table with a specific case. The value is also used as a descriptor in the nodal output tables.
-
Case Network FileCase Network File
The path and filename of the file that holds the nodal case data. The file is produced by converting a "raw” output file from a loadflow study into the format required by Aurora through the raw file conversion capability found on the Input Data Assumptions Toolbar.
-
Case Start DateCase Start Date
The start date for use of the case within the study period. Aurora will use one case until the start date of another is reached and then will switch to the next case. The same case maybe used more than once if desired through multiple row entries and starting dates referencing the same case.
Shift Factor Handling

-
Use this field to specify a new or existing .bin file.
The Shift Factor File is a binary file that may be optionally used to save the shift factors calculated for a given network case input file and study configuration. For large systems (20,000 buses or more) it may take several minutes to solve for the shift factor structure. If the same configuration will be run several times, time can be saved by storing the values in this file the first time they are solved (see Save on Solve below), and then re-read directly from the hard drive for subsequent runs.
Shift factors are used to determine branch flows as functions of net load at each bus. For each MW of load/gen at a particular bus they tell us how much is flow going to increase (or decrease) on a particular branch. There can be a number of values for bus/branch pairs. Note that load on a bus can affect flows on branches to which the bus is not directly connected, so the shift factors can be a very large data set.
The Shift factor tolerance is a level below which the model ignores the shift factors. A lower value in that setting means that the model accounts for smaller numbers and keeps track of more shift factors.
 NOTE: This file can be extremely large. A 20,000 bus system can easily generate a Shift Factor File of 500 MB or more.
NOTE: This file can be extremely large. A 20,000 bus system can easily generate a Shift Factor File of 500 MB or more. -
If Save on Solve is TRUE, Aurora will store the values for the shift factor in a binary (.bin) file, as specified in the Shift Factor File column.
NOTE: A new or existing file name must be specified in the Shift Factor File field (see above) in order to save the binary file for future use. If no file name is specified, Aurora creates a temporary file that is discarded at the end of the run. If the specified file already exists, Aurora will replace the contents of that file with any changes to the network structure. -
This entry controls the sequence of actions Aurora goes through when determining the shift factors to use for a network dataset. Shift factors are checked or solved each time a network dataset changes during the course of a study.
Available values for the Shift Factor Action are:
-
Solve Always - the model will always solve the current network topology to get a current set of shift factors.
-
Solve on Diff - if chosen and a Shift Factor File is specified for the case, Aurora will read the Shift Factor File and compare cross-check information stored in the file to determine whether the network associated with the saved data is identical to the current system being analyzed. Checks are done on slack bus, number of buses, number of branches, branch reactances, the list of injection buses required, and the list of buses required for contingency evaluation. If the cross-check passes, the stored factors are used. If the cross-check fails, a new solution for the shift factors is performed.
-
Stop on Diff - if chosen, the same crosscheck is performed, but Aurora will stop if the crosscheck fails.
NOTE: A Shift Factor File must be specified in the Shift Factor File field (see definition above) in order to use the Solve on Diff and Stop on Diff actions. -
LODF Handling

-
Use this field to specify a new or existing .bin file.
The LODF File is a binary file that may be optionally used to save the LODFs calculated for a given network case input file and study configuration. If the same configuration will be run several times, time can be saved by storing the values in this file the first time they are solved (see Solve Action below), and then re-read directly from the hard drive for subsequent runs.
A new study will use as much of the saved file as necessary. For instance, if you save an LODF file for a set of contingencies and then delete some records later, you can still reuse the file and only LODFs for active contingencies will be loaded from the file. However, in this example if you have also selected Save on Solve then this new, smaller set of contingencies will overwrite the larger set of contingencies in the original file. If this is not desired, then you should not select Save on Solve for subsequent runs after saving a larger contingency file.
If the list of contingencies saved in the file is smaller than what is currently in the table, then the additional LODFs needed for the new contingencies will be calculated. If Save on Solve is selected in this example, then the new, larger set of contingencies will be saved.
Note that Save on Solve basically takes the current case list of contingencies and saves them to the file regardless of what was in the file before. If nothing has changed then nothing new will be saved. If Save on Solve is not selected then the file will not be changed.
The model identifies a contingency by the IDs as specified in the Contingency table. If an ID is changed, then it will be viewed as a new contingency.
-
If Save on Solve is TRUE, Aurora will store the values for the LODFs in a binary (.bin) file, as specified in the LODF File column.
NOTE: A new or existing file name must be specified in the LODF File field (see above) in order to save the binary file for future use. If no file name is specified, Aurora creates a temporary file that is discarded at the end of the run. If the specified file already exists, Aurora will replace the contents of that file with any changes to the network structure. -
This entry controls the sequence of actions Aurora goes through when determining the LODFs to use for a network dataset. LODFs are checked or solved each time a network dataset changes during the course of a study.
Available values for the Solve Action are:
-
Solve Always - the model will always solve the current network topology to get a current set of LODFs.
-
Solve on Diff - if chosen and a LODF File is specified for the case, Aurora will read the LODF File and compare cross-check information stored in the file to determine whether the network associated with the saved data is identical to the current system being analyzed. Checks are done on slack bus, number of buses, number of branches, branch reactances, the list of injection buses required, and the list of buses required for contingency evaluation. If the cross-check passes, the stored factors are used. If the cross-check fails, a new solution for the shift factors is performed.
NOTE: A LODF File must be specified in the LODF File field (see definition above) in order to use the Solve on Diff action. -

-
Flow Limit ColumnFlow Limit Column
This field defines which Limit columns in both the Loadflow_Branch and Loadflow_Transformer tables are used for flow limits. If the entry is blank, or the column name is not found in the table, the “Limit” column will be used by default. A message is written to the NodalStudyLog listing the columns used for input.
-
Contingency Limit ColumnContingency Limit Column
This field defines which Limit columns in both the Loadflow_Branch and Loadflow_Transformer tables are used for contingency flow limits. If the entry is blank, or the column name is not found in the table, the base flow limit data (Flow Limit Column above) will be used by default. A message is written to the NodalStudyLog listing the columns used for input.
See Equivalence Radials for more information on reducing nodal problem size and speed of solution by eliminating radial lines within a loadflow case.