Input Tables Window 
The Input Tables Window is the principal tool for input dataset management in Aurora. The Input Tables Window is used to access, modify, organize and manage all of the input data used in a study including Zonal Input Data tables, Nodal Input tables, and Nodal Network Definition Datasets. It is also used to create and manage Change Sets, which represent incremental sets of data changes to the underlying database.
Input Tables Toolbar
The toolbar ribbon is located at the top of the Input Tables Window. See Input Tables Toolbar for more information.
Change Sets
The task pane on the far left of Input Tables Window is used to manage Change Sets.
Data Grid
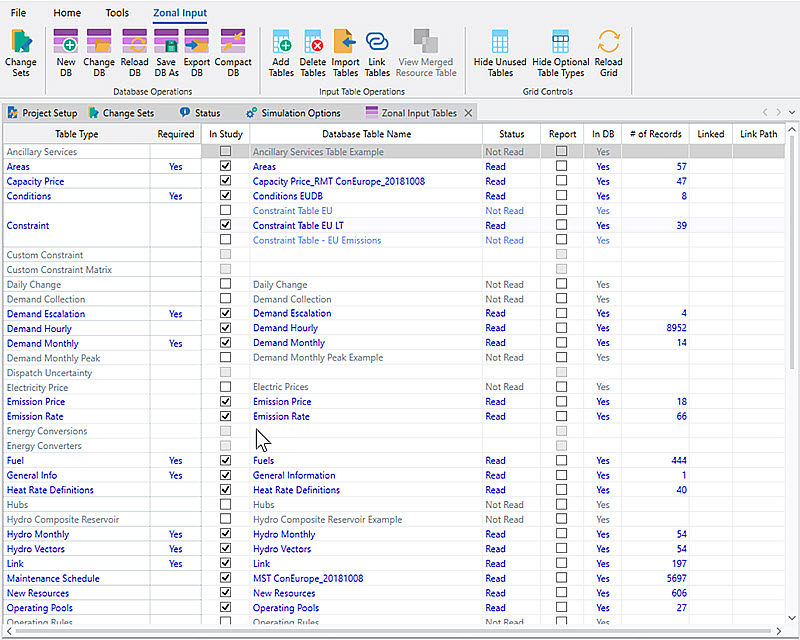
The grid in this window is a view into all of the tables in the project input database and their current status in the project. When a project is opened the referenced input database is examined, and the model will automatically determine the type of each table in the database using the table’s column names. Aurora will start a background thread to read each valid table into memory if it is selected for inclusion in the study. The status of the input table reads is shown in the status bar at the bottom of the Main application window. The name and path of the active database is listed at the bottom of the window.
Data Grid Columns
The Data Grid in the Input Data Assumptions window is used to select tables or data for use in a study and for informational purposes. Some columns cannot be edited within this grid. See Data Grid Columns for more information.
View or Edit Input Tables
To view or edit a data table, select the table name and double-click. You can also select the table name, right-click, and select Edit Table from the pop-up menu. See Editing Database Tables for information on editing data within a table.
Data Grid Right-Click Menu
A right-click within the data grid will bring up a pop-up menu. This allows easy access to the common operations performed on input tables. See Data Grid Right-Click Menu for more information.
Color Codes in the Grid
The status of Input Tables or Nodal Input Tables is color coded within the grid, as described below:
-
Blue: Table exists in the database, is selected as 'In Study', and has been read within the project file.
-
Light Blue: Table exists in the database, is NOT selected as 'In Study', however another table of that type is 'In Study'.
-
Gray: Table exists in the database and no other table of that type is 'In Study'.
-
Faded Red: Table existed in the project and was previously selected as 'In Study', but no longer exists within the database.
-
Red: Table type is required for 'In Study' but no table of that type is selected. (Note that 'required' Nodal input data tables are only required for Nodal studies.)
See Zonal Input Data or Nodal Input Tables for more information on input tables available for an Aurora study.
![]() NOTE: When using SQL Servers for database management, Aurora can separate the input and output SQL Servers so they can be specified independently.
NOTE: When using SQL Servers for database management, Aurora can separate the input and output SQL Servers so they can be specified independently.
![]() NOTE: Ensuring Valid Data: It is possible, especially when importing or copying data from the internet, for external data sources to contain "illegal" characters (e.g., non-breaking white space commonly used on the web). Illegal characters are usually invisible and result in hard-to-find errors in Aurora. (They are generally non-printing characters or symbols that have a Unicode char range <32 or >127.)
NOTE: Ensuring Valid Data: It is possible, especially when importing or copying data from the internet, for external data sources to contain "illegal" characters (e.g., non-breaking white space commonly used on the web). Illegal characters are usually invisible and result in hard-to-find errors in Aurora. (They are generally non-printing characters or symbols that have a Unicode char range <32 or >127.)
![]() Input Tables Window
Input Tables Window